Современные нейросети, такие как ChatGPT и GPT-4, обладают поразительной способностью генерировать текст, который выглядит убедительно и связно. Однако часто они сталкиваются с проблемой: их ответы могут быть неактуальными или даже неверными, особенно когда дело касается специфических данных. Основная причина — отсутствие привязки к свежим и персонализированным данным пользователей.
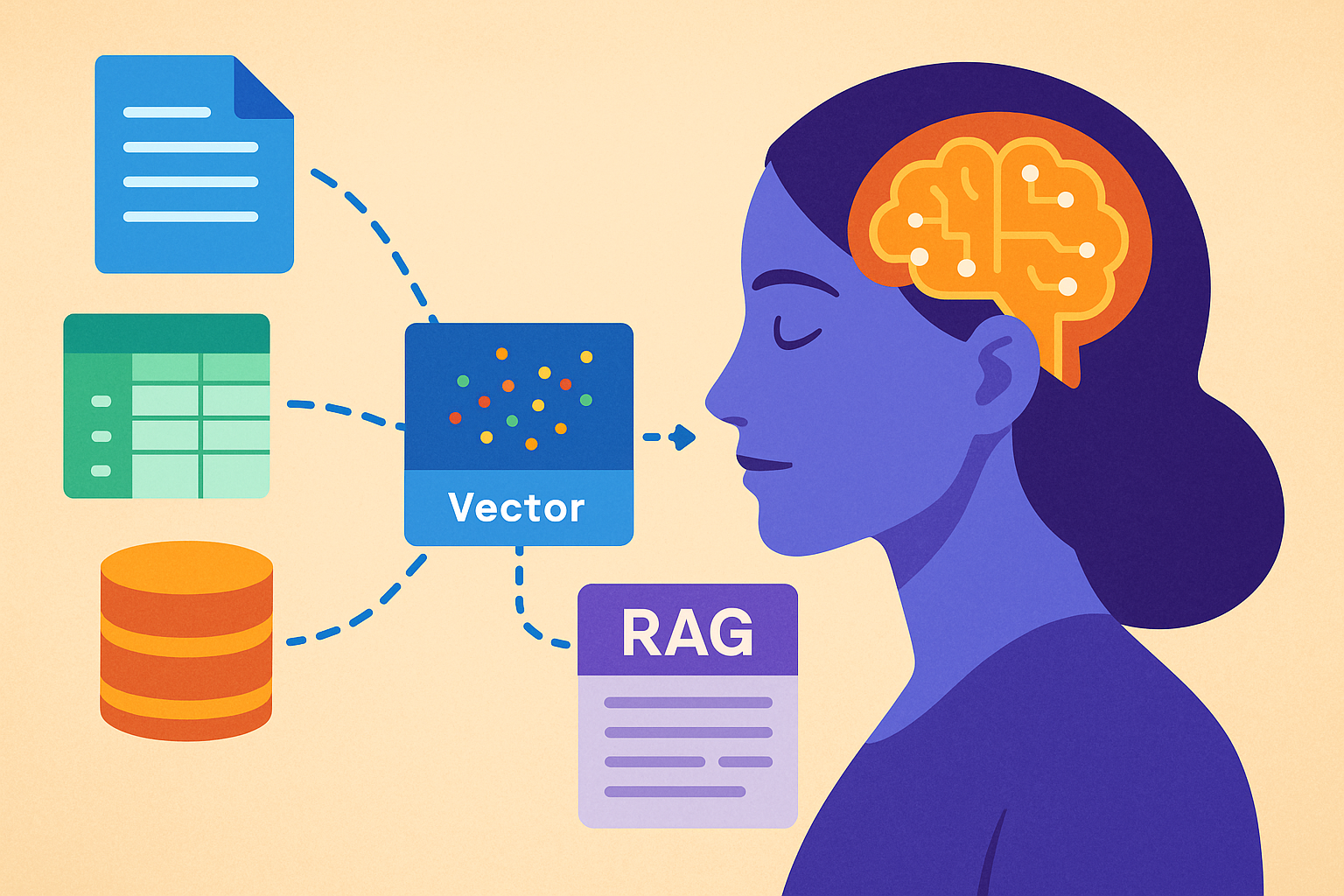
Именно здесь на помощь приходит Retrieval-Augmented Generation (RAG) — технология, способная революционизировать способ работы AI с вашими данными. RAG интегрирует внешние источники информации, такие как документы, таблицы и базы данных, в процесс генерации ответов, тем самым повышая их точность и актуальность.
Что такое RAG?
Retrieval-Augmented Generation, или RAG, — это подход, который совмещает в себе возможности поиска информации и генерации текста. Представьте себе нейросеть, которая имеет доступ не только к интернету, но и к вашим личным данным: папкам с документами, таблицам в Excel или Google Sheets. Она выполняет три основных этапа: поиск данных, их выборка и генерация ответа. Это как если бы у нейросети был встроенный “гугл”, но ограниченный вашими собственными источниками информации. Такой подход позволяет AI выдавать ответы, опираясь на актуальные и проверенные данные, что значительно улучшает качество и точность ответов.
Как работает RAG?
Компоненты RAG
-
Retrieval (Поиск): на этом этапе система ищет релевантные документы или данные, которые могут содержать ответ на заданный вопрос. Это осуществляется через векторные базы данных, такие как Pinecone, Weaviate или FAISS, которые позволяют быстро находить нужную информацию.
-
Augmentation (Дополнение): найденные данные интегрируются в контекст, который будет использоваться для генерации ответа. Это похоже на добавление источников информации в разговор, что делает его более осмысленным и точным.
-
Generation (Генерация): на основе обогащенного контекста нейросеть генерирует ответ. Используя данные, найденные на предыдущих этапах, она способна выдать более релевантный и точный результат.
Роль эмбеддингов и векторных баз
Чтобы процесс поиска был эффективным, данные преобразуются в эмбеддинги — числовые представления, которые позволяют компьютеру понимать и находить семантически схожие записи. Векторные базы данных хранят эти эмбеддинги, что облегчает поиск нужной информации. Это ключевой элемент, обеспечивающий оперативную работу RAG.
Зачем RAG бизнесу?
Актуальные ответы без обучения модели: одно из главных преимуществ RAG — возможность предоставлять точные и актуальные ответы без необходимости регулярного обучения модели. Это особенно полезно, когда данные часто обновляются.
Безопасность данных: поскольку RAG работает с приватными источниками, компании могут быть уверены в безопасности своей информации. Это критично для отраслей, где конфиденциальность является приоритетом.
Быстрая адаптация под нишу: RAG легко адаптируется под различные бизнес-сферы. Например, в e-commerce можно генерировать описания товаров, в финансах — анализировать отчеты, а в медицине — работать с медицинскими картами.
Примеры использования
Для маркетолога
С помощью RAG нейросеть может анализировать прошлые маркетинговые кампании и генерировать новые идеи для постов или рекламных текстов, основываясь на успешных примерах из прошлого.
Для аналитика
Аналитики могут задавать вопросы, касающиеся свежих данных из Google Sheets, и получать ответы, которые учитывают последние изменения и тенденции.
Для e-commerce
RAG может автоматически генерировать описания товаров, учитывая их характеристики, указанные в таблицах. Это позволяет быстро и эффективно обновлять информацию на сайте.
Интеграция RAG с Google Sheets
Как же происходит интеграция RAG с такими инструментами, как Google Sheets? Ваш SaaS-продукт может автоматически извлекать данные из таблиц, преобразовывать их в векторный индекс и передавать ИИ для обработки. Например, это позволяет массово генерировать карточки товаров, автоматизировать ответы на клиентские запросы или готовить отчеты. Такой подход облегчает работу с большими объемами данных и делает её более точной.
Ограничения и подводные камни
Хотя RAG открывает впечатляющие возможности, у технологии есть ряд особенностей и ограничений, которые важно учитывать при внедрении:
- Качество эмбеддингов и векторного поиска: если эмбеддинги построены на слабой модели или с неправильными параметрами, поиск будет возвращать нерелевантные документы. Неправильно выбранная размерность или алгоритм индексации (например, в FAISS или Pinecone) может замедлить поиск или снизить точность.
Пример: При использовании старой модели эмбеддингов «вопрос: условия доставки» может подтянуть документ про оплату — и ответ получится бессмысленным.
- Актуальность и полнота источников: RAG выдаёт только то, что есть в базе. Если данные неполные или устаревшие — ответы будут неполными или ошибочными. Требуется регулярное обновление индекса: добавление новых документов и удаление неактуальных.
Важно: В отличие от интернет-поиска, модель не «догадает» недостающую информацию, если она отсутствует в ваших источниках.
- Чувствительность к формулировкам запроса: разные формулировки могут возвращать разные документы. Без качественной настройки поиска и перефразировки запросов (query rewriting) можно потерять нужную информацию.
Совет: иногда полезно дополнительно нормализовать запросы или использовать перефразировщики перед поиском.
-
Риск «галлюцинаций» даже с контекстом: RAG снижает, но не полностью исключает, генерацию выдуманных фактов. Модель может интерпретировать данные неправильно или дополнить их собственной «фантазией».
-
Затраты на инфраструктуру: хранение векторных индексов для больших массивов данных требует ресурсов. Построение и обновление индексов может быть затратным по времени и деньгам, особенно при больших объёмах информации.
-
Ограничения по типу данных: текущие RAG-системы лучше работают с текстом. Сложные форматы (PDF с графиками, изображения, аудио) требуют отдельной обработки и могут терять часть информации при конверсии.
Пример: Для смешанных типов данных нужна мультимодальная архитектура: текст обрабатывает языковая модель, таблицы — парсер, изображения и графики — компьютерное зрение, после чего всё объединяется в общий векторный индекс для работы RAG.
- Проблемы безопасности и прав доступа: если в индекс попали конфиденциальные документы, они могут случайно оказаться в ответе. Нужно внедрять контроль доступа и фильтрацию результатов перед генерацией.
Выводы
RAG — это нейросеть, которая может говорить с вами на языке ваших данных, предоставляя актуальные и точные ответы. Она открывает новые возможности для бизнеса, улучшая работу с информацией и способствуя повышению эффективности процессов.